

The MIT study that could change how UX researchers use AI
Why doing research work yourself first might be better than going "AI first"

Ask a few researchers about using LLMs for tasks like generating draft usability test scripts, and you’ll get wildly different answers depending on when you asked.
The researcher who tried it two years ago might dismiss it as producing generic, unusable output. The one experimenting today might find it surprisingly helpful for initial structure and probing questions. By next year, both perspectives could be obsolete, as indeed, LLMs continue to quickly evolve, with capabilities roughly doubling every seven months by one estimate.
A deeper challenge is that traditional evaluation methods fall short. Even if one conducted rigorous studies comparing AI-assisted versus human-only research processes, those findings would be outdated by the next frontier model release. This reality demands a different approach than the typical “best practices” playbook. We can’t rely on checklists, curated prompt libraries, or even broad mental models that cast AI as a “research assistant” or “brainstorming partner.” These frameworks become brittle too quickly.
Instead, let’s focus on something more stable: how humans interact with these tools. While LLMs rapidly change, human cognition is the product of a slow evolutionary process, and is unlikely to shift too quickly. Studies are finally starting to reveal patterns in how human cognition and artificial intelligence interact.
Introducing a recent MIT study
A June 2025 study with the memorable title “Your Brain on ChatGPT” by MIT scholars Nataliya Kosmyna and colleagues has garnered much attention. You can read the full 206 page preprint manuscript, but let’s briefly summarize what they did and found.

The authors recruited a total of 54 adult participants in the Boston area, and randomly assigned them into one of three groups: one that used LLMs, one that used search engines, and one that worked without outside tools (humorously termed Brain-only in the manuscript). Participants in each group were asked to write on different general interest essay topics over four sessions of 20 minutes each. In the first three sessions, although the topics would vary, participants could use only those tools described in their group assignment. The last session, which was optional (and had only 18 participants) swapped the members of the LLM group to Brain-only and vice versa, and prompted them to revisit a topic they had written on in a previous session. Below is a figure developed by the authors representing the study design.
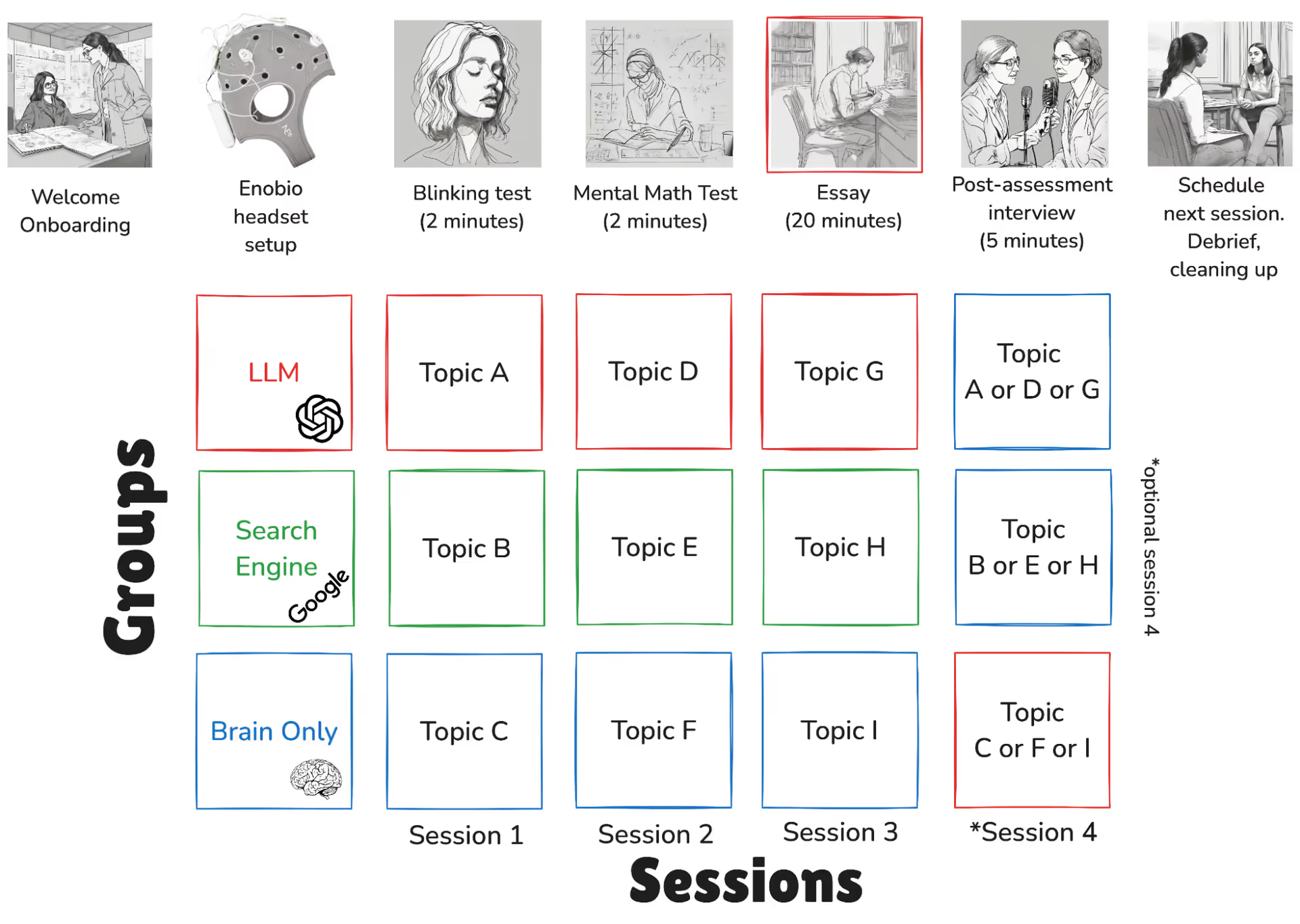
This study has two interesting elements that contrast it with similar studies to date. First, they used EEG (electroencephalography) to measure brain signals. Although any measurement has its tradeoffs — EEG’s spatial resolution is limited — this gives us some indication of how LLM usage affects brain activity, such as cognitive effort. Second, it took place over four months. While a relatively short period of time, this longitudinal element provides a window into how patterns of brain activation change over time with repeated behavior.
What were the findings?
The most pertinent results come from comparisons between the LLM and Brain-only groups.
Compared with Brain-only participants, LLM participants’ essays were longer, more similarly structured, and less diverse in ideas and content. That should come as no surprise to anyone who’s spent much time on LinkedIn lately, which promotes AI-generated posts within the interface, and where the feed often feels gratingly uniform in style and tone.
In survey and interview responses, LLM participants felt less of a sense of ownership than the Brain-only group. This seems appropriate, even expected, given that LLM participants’ were largely using the outputs given them, instead of working hard to produce them. By the third session, authors summarize LLM participants’ essays as “mostly copy-paste [with] minimal editing”. This further showed up in EEG measurements, with lower activation and cognitive effort over the first three sessions. But this lower effort came at the cost of being able to recall specific quotes from the co-written text, which LLM participants had a much harder time doing.
So much for the first three sessions. What happened in the final session when the groups were switched?
Having revisited an essay topic they had already spent significant cognitive effort writing on, the Brain-to-LLM group’s EEG measurements showed a huge boost in cognitive activation suggesting “high levels of cognitive integration, memory reactivation, and top-down control.” Although they hadn’t used an LLM in previous sessions, their prompts were actually more sophisticated, i.e. more “information-seeking.” And even with the assistance of an LLM, they maintained a higher recall of the produced text than the previous LLM-only group.
As for the LLM-to-Brain group, their neural connectivity and engagement remained low. Nevertheless, their essays were rated highly by human judges — perhaps because they apparently reused phrasing and structures learned from previous interactions with LLMs on the topics.
Implications for user researchers
What might this mean for user researchers — who are under increasing pressure these days to deliver insights more quickly or to fall in line with company initiatives to go “AI first”?
For many reasons, we mustn’t be quick to over-interpret or generalize the results of a single study, even if some of its results have been seen in studies in other contexts. For one thing, this is a preprint on arXiv — which means it hasn’t yet been subjected to peer review, the standard for good science. A relatively small sample of only 18 participants completed the final and most interesting “switching” session. Further, artificial tasks in a laboratory with an EEG monitor on your head don’t exactly resemble the real world, and some of those differences may be important. That said, there’s a logical plausibility to the findings, and I (and I imagine many readers who have experimented with LLMs at work will) recognize some similarity in the overall pattern of results with personal experience.
Takeaway 1: The performance benefits of LLMs likely come with cognitive tradeoffs. To date, most studies of LLM usage in the workplace focus on performance outcomes, namely how quickly tasks are completed (i.e., efficiency) and how well the tasks are done (i.e. quality). Most — though not all — studies of this kind point to enormous benefits. Likewise, in the MIT study, the LLM group’s essays were judged as “deeper” and technically superior, even if one judge called them “soulless.” Interestingly, the most highly-rated essays were those produced in Session 4 by participants without LLMs who had previously written on the topic with an LLM’s help, suggesting they had learned to imitate the style and structure of LLM outputs.
Nevertheless, these benefits aren’t without costs. Many have already pointed out societal costs, whether the energy demands and ecological impacts of AI datacenters, or the ethical quandaries of using models trained on human-authored works without consent or compensation. But few, if any, studies have yet looked at the drawbacks to human cognition, and it turns out there isn’t a free lunch here either.
Takeaway 2: Outsourcing thinking likely means outsourcing learning and comprehension. One of the most commonly-touted benefits of LLMs is that they solve the “blank page” problem of getting a first draft going. And in my own experience, I have found LLMs excel in low stakes situations like drafting one-off communications such as an email asking for a refund. These are things I just want to get off my plate, that I have no desire to become an expert in doing. But when it comes to those things we want expertise in, going “AI first” will backfire.
Researchers, like other tech professionals and knowledge workers broadly, often have more tasks than time in which to do them. Allocating equally-intense cognitive resources to every task isn’t a winning strategy, if it’s even possible. So using LLMs can be one tool to offload some of that effort. But if these results are generalizable, asking an LLM to take the first pass at any deliverable relevant to our job function (whether a discussion guide or a report of findings) will leave us understanding it in an only superficial way. When we need to speak for those deliverables with stakeholders, we’ll be less authoritative and less persuasive as collaborators. It may even hamstring us later if we decide or need to do those tasks ourselves.
Takeaway 3: There may be an “optimal sequence” for LLM usage. Contrary to some popular accounts of the study, the point isn’t that LLM usage was unequivocally bad for the brain. (The authors specifically warn against drawing the conclusion that LLMs make people “dumber.”) The Brain-to-LLM group, which was given the chance to revisit (with an LLM) a topic previously written upon (without assistance), showed deeper engagement with the task and more nuanced usage of the tool.
In other words, you can potentially offset the downsides of LLM outsourcing by largely doing the work yourself first. In his comments on this study, Ethan Mollick, a University of Pennsylvania professor who has published extensively on the performance benefits of LLMs, plainly states that one should “become disciplined” and generate their own ideas and drafts before consulting with these tools.
Virtually every tool and SaaS product built to support user and market research work has in recent years added AI-powered functionalities — whether for drafting study questions, moderating interviews, analyzing data, etc. But for any professional wishing to develop expertise in research (and its component skills), turning first to these features may be counterproductive. At best (setting aside open questions about the reliability and biases of these tools), they may be helpful for non-specialists who have no wish to learn research. Otherwise, specialists should do the work first and (if desired) later compare with what these tools can generate to tweak and improve it.
I say “if desired” because — for now, at least, and based on these results — the performance benefit of using an LLM once you’ve already done the work is less clear. This isn’t to say there are none, but it wouldn’t show up in the efficiency savings observed in previous studies, and it didn’t emerge in human judgments of quality in this study.
The bottom line
Past studies on how people use LLMs at work have pointed to their upside with performance benefits and their downside with reliability issues (like hallucinations). On that latter point, since we’re still seeing rapid technical improvements in LLMs from week to week, there remains cautious optimism that present issues might be solved.
Nevertheless, human cognition changes slowly over many generations, so the effects of LLM use on our intelligence is unlikely to change. A recent study from MIT shows that over-reliance on LLMs effectively stunts learning and memory related to the task, which should make professionals interested in developing research expertise think twice about going to them first.
We shouldn’t consider the MIT study definitive — there’s more work to be done — but I’d argue it warrants our attention. For now, the best strategy may be to do research-related work yourself first before comparing against the output of either a general purpose LLM like ChatGPT or a research-tuned AI tool. I hope future studies will take a closer look at the benefits of alternative approaches. For instance, there may be effective more granular sequences, such as outlining with an LLM’s help before drafting the text yourself. If nothing else, this study highlights the need for a more nuanced look at how artificial and human intelligence interact.
I wonder if teams using the AI-first approach to process raw data, produce summaries and actionable insights have different long term outcomes.
It would be interesting to know if the lowered learning and memorability of the task results in lowered impact of UX research.
Great read! I resonate with the ownership finding a lot. I recently saw a post where people were discussing doing a PhD before AI and now, and how “easy” it is today to do a literature review. I think we need to remember that the easy part has a cost in missed skills 😁