

Six UX benchmarking mistakes to avoid
How to get the most out of your UX benchmark


UX benchmarking1 is a method that combines task-based behavioral metrics and attitudinal ratings to obtain a reference-point measure of a product’s user experience. This helps UX teams and stakeholders identify the relative strengths and weaknesses of a user experience, measure the impact of design efforts, and prioritize future work.
Unfortunately, they can be intimidating to folks who aren’t experienced with them and are prone to costly mistakes. You can avoid these pitfalls with careful planning and documentation.
In this article, we will highlight some of the most common mistakes people make when running their first benchmark, and provide you with tips and best practices to approach your baseline benchmark with confidence.
Six UX benchmarking mistakes to avoid
Planning in isolation
UX benchmarks are a valuable resource for stakeholders across organizations. Design, research, product management, marketing, sales, engineering, and others can benefit from the insights they generate. So, an early mistake a UX researcher can make is not involving stakeholders in the planning phase of a baseline.
Don’t plan your benchmark alone. Failing to involve people from different functions can undermine your research plan and limit the impact of your findings. If stakeholders aren’t involved in the planning process, they may not feel a sense of ownership over the benchmark or its results. In turn, they may reject your findings and resist your recommendations. Further, they may have resources (e.g., analytics, reports & data, budget) and information (e.g., organizational context and goals) that can strengthen a benchmark when integrated into the planning process.
By actively involving folks from other teams, UX researchers can capitalize on the shared knowledge and resources of their wider organization and increase buy-in and engagement from cross-functional teammates.
Making a poor sample size decision
Precise measures are critical to benchmarking results and how we use them. Therefore, one of the worst choices a UX practitioner could make is selecting too low of a sample size for their study.
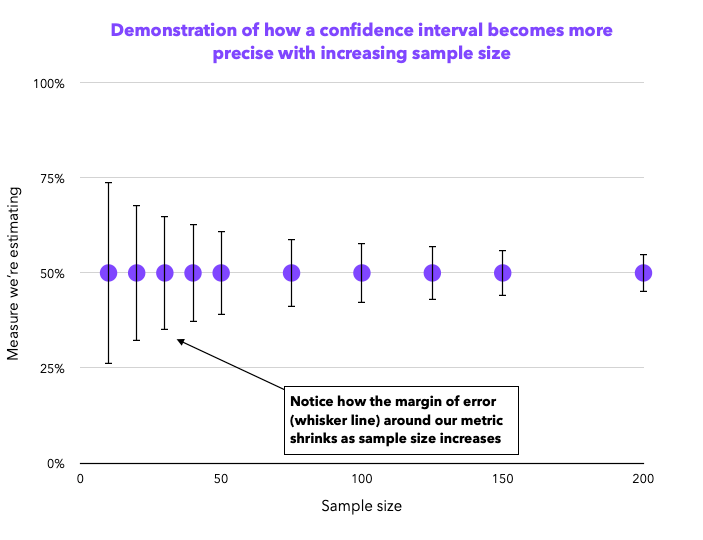
With their quantitative nature, benchmarks tend to have higher sample sizes. The higher the sample size you collect, the more precise your measures become. We can visualize this with confidence intervals, which display a range representing the certainty around our measurement. At a low sample size, your metrics have a wide range of probable values.
In the example above, you can see at a sample size of n= 10, our likely range for task success rate is 26-74%. The same result with a sample size of n= 200 would give us a range of 45-55%; much more precise. Note that increasing sample size initially reduces the margin of error significantly, but further increases have diminishing returns.
Generally, you want to collect a high enough sample size for a practically significant margin of error. Practical significance will be different for everyone, but ask yourself, “How much of a difference do we have to find for it to matter to us?” This consideration helps with the confidence around results in any individual benchmark and makes it easier to demonstrate meaningful differences in repeat tests2.
Choosing tasks…too many, too few, or too small
For most products, it is impractical to test everything a user can do. Choosing the right tasks is crucial for relevant benchmarking efforts. But, people often make mistakes in task selection.
Many groups will select too many tasks, leading to time-consuming and resource-intensive benchmarking projects that have difficulty getting off the ground. Some groups select too few tasks; leading to incomplete benchmarking that only captures a small portion of what matters to users. Finally, some groups will choose tasks that are too small in scope (e.g., “find the signup button”). These types of small, isolated tasks lead to superficial insights and miss the bigger picture of user experience.

Effective benchmarking needs a prioritized set of 5-10 representative user tasks. Each task should represent a user goal with an observable start and end point (e.g., “log in and pay your bill for December”). You may choose to run a top tasks analysis to help prioritize candidates. In this method, you list every user task and enter them into a survey where you’ll ask participants to select the five most important to them. The results of top task analyses usually show a “long neck” pattern, where a small number of tasks are frequently considered the most important. These ought to be the tasks you benchmark.
Going overboard on metrics
It's easy to go overboard and include several metrics in your study plans. Sometimes you might be tempted to include a few that measure the same construct. For example, I’ve seen studies that measure the SUS, UMUX-lite, NASA-TLX, and SMEQ. This is counterproductive; one of the most common mistakes a first-time benchmarker makes is including way too many metrics.
Collecting too many metrics increases the effort required for planning, executing, and analyzing your study, increases response times and dropoff rates for participants, and dilutes the focus of the findings & report. Your benchmark should have a focused measurement plan with an appropriate amount and breadth of meaningful metrics.
“The extent to which a system, product or service can be used by specified users to achieve specified goals with effectiveness, efficiency and satisfaction in a specified context of use”
A good starting point for a measurement plan would be to pick a metric corresponding to each of the primary factors of usability: effectiveness, efficiency, and satisfaction. For example, you may measure task success rate (effectiveness), time-on-task (efficiency), and post-task SEQ plus post-test UMUX-lite (satisfaction).
Forgetting the ‘So what?’ and ‘Now what?’ in reports
Getting the results of your first benchmark is exciting. Analyzing the data, calculating the metrics, and visualizing the results in a report can feel like the payoff for your careful planning. But, it would be a common mistake to stop your report there. Without adding commentary, conclusions, and recommendations to the data, you leave your audience asking, “So what does this mean?” and “Now what do we do about it?”

Benchmarking reports shouldn’t be limited to the output data, metrics, and graphs from our analyses. Non-UXR stakeholders won’t be familiar enough with UX metrics to know how to interpret results without added headlines, takeaways, and recommendations. For each finding you present in your report, follow the What, So what, Now what framework to help readers understand what you found, why it matters, and what they can do about it.
What — Tell your reader what you found by including, metrics, graphs, and verbal descriptions of your findings.
So what — Tell your reader why what you found matters by expanding on what you, as the research expert, see in the data and the implications that result has on users. Explain the consequence of your findings. For example, if you’ve found that task success rate is low, explain why that matters to users and how it impacts them.
Now what — Finally, tell your reader what can be done. Explain how the team can act on the findings and improve the user experience.
By using this framework you can make sure anyone who reads your report understands the findings and implications of your UX benchmark, regardless of their background or expertise.
Not documenting your approach
Imagine you completed your baseline benchmark. Everything went outstanding; your stakeholders ate up the findings, and now they have an appetite for more.
Now, imagine it is time to conduct the second round of benchmarking, and you can't recall the setup or analysis procedures from the baseline. As a result, you struggle to ensure you’re truthfully replicating the study, waste time in the study setup, and lose confidence that you’re making apples-to-apples comparisons across studies. Many researchers find themselves in this predicament. It's a common mistake to neglect thorough documentation of benchmarking processes.
During your baseline benchmark, document every aspect of the study:
Study methodology, including the test plan, participant details, sample size, and recruitment channels
Tasks, including their starting points, success criteria, order & randomization, and phrasing for instructions
Metrics, including what you measured and how you measured it
Analysis steps, including how data was cleaned and prepared, how you calculated metrics, and which statistical comparisons you ran
Results & reporting, including how you went about turning raw findings into a cogent report, who it was shared with & how, and where it was stored
Documenting these items will produce a guide any researcher on your team can use to consistently replicate benchmarks time-over-time, and increase their ability to draw meaningful comparisons between tests.
The bottom line
Benchmarks are a valuable tool for understanding the relative strengths and weaknesses of a user experience. However, they can be challenging to plan and execute, especially for those new to the method. By being aware of common pitfalls, a researcher can increase their chances of setting up an effective baseline benchmark that can flourish into a successful, recurring program.
Key points to follow:
Involve stakeholders from cross-functional teams to promote buy-in and capitalize on shared information & resources when planning benchmarks
Collect a sufficient sample size to get precise and meaningful estimates of your metrics
Prioritize a set of 5-10 representative user tasks
Be selective in the metrics you collect & analyze; pick metrics to capture effectiveness, efficiency, and satisfaction
Contextualize your findings, why they matter, and how to act on them in your report
Document your methods, tasks, metrics, and analyses to make replication easier